
Responsible Engineering
Software systems deployed in the real world can be a source of many forms of harm, small or large, obvious or subtle, easy to anticipate or surprising. Even without machine learning, we have plenty of examples of how faults in software systems have led to severe problems, such as massive radiation overdosing (Theract-25), disastrous crashes of spacecrafts (Ariane 5), losing $460 million in automatic trading (Knight Capital Group), and wrongly accusing and convicting 540 postal workers of fraud (Horizon accounting software). With the introduction of machine-learning components, learned from data and without specifications and guarantees, there are even more challenges and concerns, including the amplification of bias, leaking and abuse of private data, creating deep fakes, and exploiting cognitive weaknesses to manipulate humans.
Responsible and ethical engineering practices aim to reduce harm. Responsible and ethical engineering involves many interrelated issues, such as ethics, fairness, justice, discrimination, safety, privacy, security, transparency, and accountability. The remainder of this book will explore steps practitioners can take to build systems responsibly.
Legal and Ethical Responsibilities
The exact responsibility that software engineers and data scientists have for their products is contested. Software engineers have long gotten away (arguably as one of very few professions) with rejecting any responsibility and liability for their software with clauses in software licenses, such as this all-caps statement from the open-source MIT license, which is mirrored in some form in most other commercial and open-source software licenses:
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
This stance and such licenses have succeeded in keeping software companies and individual developers from being held liable for bugs and security vulnerabilities. With such licenses, it has even been difficult to adjudicate negligence claims. Liability discussions are more common around products that include software, such as medical devices, cars, and planes, but rarely around software itself.
There is some government regulation to hold software systems accountable, including those using machine learning, though many of these stem from broader regulation. For example, as we will discuss, there are various anti-discrimination laws that also apply to software with and without machine learning. Emerging privacy laws have strong implications for what software can and cannot do with data. In some safety-critical domains, including aviation and medical devices, government regulation enforces specific quality-assurance standards and requires up-front certification before (software-supported) products are sold. However, regulation usually only affects narrow aspects of software and is often restricted to specific domains and jurisdictions.
Even though developers may not be held legally responsible for the effects of their software, there is a good argument for ethical responsibilities. There are many actions that may be technically not illegal, but that are widely considered to be unethical. A typical example to illustrate the difference between illegal and unethical actions is the decision of pharma CEO Martin Shkreli to buy the license for producing the sixty-year-old drug Daraprim to subsequently raise the price from $13 to $750 per pill: all actions were technically legal and Shkreli stood by his decisions, but the 5,000 percent price increase was largely perceived by the public as unethical and Shkreli was vilified.
While the terminology is not used consistently across fields, we distinguish legality, (professional) ethics, and morality roughly as follows:
-
Legality relates to regulations codified in law and enforced through the power of the state. Professionals should know the relevant laws and are required to abide by them. Violating legal constraints can lead to lawsuits and penalties.
-
Ethics is a branch of moral philosophy that guides people regarding basic human conduct, typically identifying guidelines to help decide what actions are right and wrong. Ethics can guide what is considered responsible behavior. Ethics are not binding to individuals, and violations are not punished beyond possible public outcry and shaming. In severe cases, regulators may write new laws to make undesired, unethical behaviors illegal. The terms ethics and morality are often used interchangeably or to refer to either group or individual views of right and wrong.
-
Professional ethics govern professional conduct in a discipline, such as engineering, law, or medicine. Professional ethics are described in standards of conduct adopted more or less formally by a profession, often coordinated through an organization representing the profession. Some professions, like law and medicine, have more clearly codified professional ethics standards. Professional organizations like the ACM have developed codes of ethics for software engineers and computer scientists. Professional organizations may define procedures and penalties for violations, but they are usually only binding within that organization and do not carry civil or criminal penalties.
We may, individually or as a group, consider that drastically raising the price of a drug or shipping software without proper quality control is bad (unethical), but there is no law against it (legal). Professional ethics may set requirements and provide guidance for ethical behavior—for example, the ACM Code of Ethics requires to “avoid harm (1.2)” and “strive to achieve high quality in both the processes and products of professional work (2.1)”—but provide few mechanisms for enforcement. Ultimately, ethical behavior is often driven by individuals striving to be a good person or striving to be seen as a good person. High ethical standards can yield long-term benefits to individuals and organizations through better reputation and better staff retention and motivation. Even when not legally required, we hope our readers are interested in behaving responsibly and ethically.
Why Responsible Engineering Matters for ML-Enabled Systems
Almost daily, we can find new stories in traditional and social media about machine-learning projects gone wrong and causing harm. Reading about so many problems can be outright depressing. In the following, we discuss only a few examples to provide an overview of the kinds of harms and concerns commonly discussed, hoping to motivate investing in responsible practices for quality assurance, versioning, safety, security, fairness, interpretability, and transparency.
With a Few Lines of Code…
First of all, software engineers and data scientists can have massive impacts on individuals, groups of people, and society as a whole, possibly without realizing the scope of those impacts, and often without training in moral philosophy, social science, or systems thinking.
Simple implementation decisions like (1) tweaking a loss function in a model, (2) tweaking how to collect or clean data, or (3) tweaking how to present results to users can have profound effects on how the system impacts users and the environment at large. Let’s consider two examples: A data scientist’s local decisions in designing a loss function for a model to improve ad clicks on a social media platform may indirectly promote content fomenting teen depression. A software engineer deploying machine learning to identify fraudulent reviews on a popular restaurant review website may influence broad public perception of restaurants and may unintentionally disadvantage some minority-owned businesses. In both cases, developers work on local engineering tasks with clear goals, changing just a few lines of code, often unaware of how these seemingly small decisions may impact individuals and society. On top of that, mistakes in software that is widely deployed or automates critical tasks can cause harm at scale if they are not caught before deployment. A responsible engineer must stand back from time to time to consider the potential impact of local decisions and possible mistakes in a system.
Safety
Science fiction stories and some researchers warn of a Terminator-style robot uprising caused by unaligned artificial intelligence that may end humanity. However, even without such doomsday scenarios, we should worry about safety. Many existing software systems, with and without machine learning, have already caused dangerous situations and substantial harms. Recent examples include malfunctioning smart home devices shutting off heating during freezing outside temperatures (Netatmo), autonomous delivery robots blocking wheelchair users from leaving a street crossing (Starship Robots), autonomous vehicles crashing (Uber). Thus, what responsibilities do software engineers and data scientists have in building such systems? What degree of risk analysis and quality assurance is needed to act responsibly?
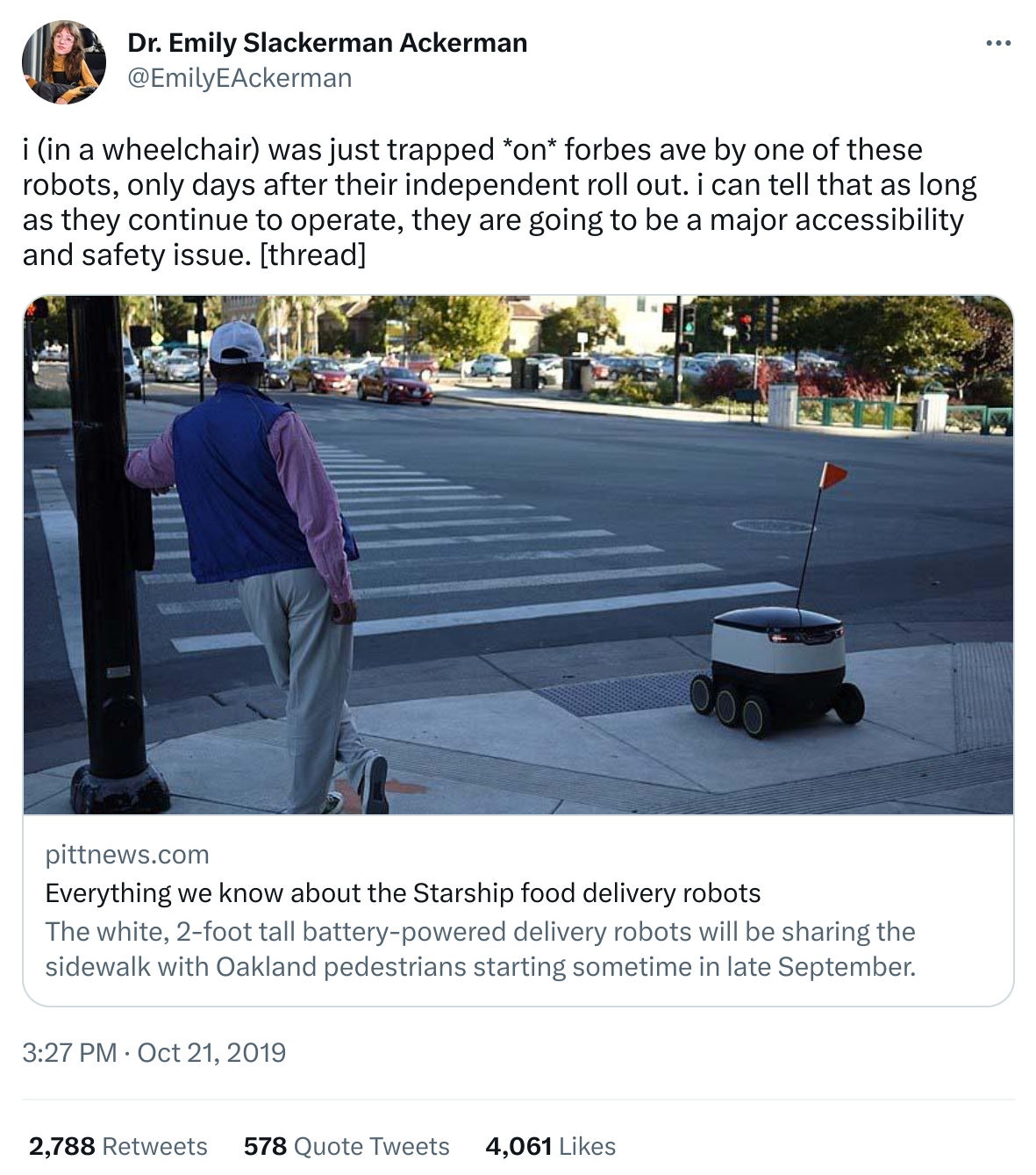
An example of a safety risk caused by an autonomous software system: a sidewalk delivery robot blocked the curbcut of a crosswalk and trapped a wheelchair user in the crossing.
Manipulation and Addiction
Machine learning is great at optimizing for a goal and learning from subtle feedback, but the system goal set by the organization and encoded by developers does not have to align with the goals of its users. For example, users of social media systems typically do not seek to maximize their time on the site and do not optimize to see as many ads as possible. Systems with machine-learning components, especially those that continuously learn based on telemetry data, can often exploit known shortcomings and biases in human reasoning—humans are not perfectly rational actors, are bad at statistics, and can be easily influenced and insecure. Machine learning is effective at finding how to exploit such weaknesses from data, for example when building systems that maximally seek our attention (attention engineering). For example, YouTube’s recommendation algorithm long overproportionally recommended conspiracy theory videos, because it learned that users who start watching one such video would often go down a rabbit hole and watch many more, thus increasing screen time and ad revenue. Similarly exploiting weaknesses in human cognition, a shopping app may learn to send users reminders and discounts at just the right time and with the smallest discount sufficient to get them to buy their products when they rationally would not. Dark patterns and gamification can lead to behavior manipulation and addiction in many domains, including games and stock trading. Bad actors can use the same techniques to spread misinformation, generate fakes, and try to influence public opinion and behavior. Hence, what is the responsibility of developers to anticipate and mitigate such problems? How to balance system goals and user goals? How can a system be designed to detect unanticipated side effects early?
Polarization and Mental Health
Social media companies have been criticized for fostering polarization and depression as side effects of algorithmically amplifying content that fosters engagement in terms of more clicks and users staying longer on the site. As models trained on user interactions identify that extreme and enraging content gets more engagement, they recommend such content, which then skews the users’ perceptions of news and popular opinions. Personalization of content with machine learning can further contribute to filter bubbles, where users see content with which they already agree but not opposing views—possibly endangering balanced democratic engagement in favor of more extreme views. In addition, the amplification of unrealistic expectations for beauty and success has been shown to be associated with mental health issues, especially among teenage girls. Hence, how can responsible engineers build systems without negative personal and societal side effects?
Job Loss and Deskilling
As machine learning can now outperform humans in many tasks, we see increasing automation of many jobs. Previously, this affected mostly repetitive jobs with low skill requirements, but the scope of automation is increasing and projected to possibly soon displace vast numbers of jobs, including travel agents, machine operators, cashiers and bank tellers, insurance agents, truck drivers, and many physicians. The positive vision is that humans will work together with machines, focus on more enjoyable and creative work, and generally work less. At the same time, many fear that humans will have less autonomy and will mostly be relegated to low-skilled manual tasks overseen by automated systems, like following instructions to pick items from a shelf, while only a few high-skilled people develop and maintain the automation systems. This increase in automation raises many concerns about inequality, human dignity, and the future of work. To what degree should responsible engineers engage with such questions while focusing on a specific short-term development project?
Weapons and Surveillance
Machine learning powers autonomous weapon systems and has been a powerful tool for surveillance. While currently most weapon systems require human oversight, some consider autonomous weapon systems making life and death decisions (“killer robots”) as inevitable (a) because human decisions are too slow against other automated systems and (b) because drones and robots may operate in areas without reliable or fast enough network connections. It is difficult to limit how machine-learning innovations may be used, and the line between search-and-rescue and search-and-destroy is thin (“dual use”). In parallel, big data and machine learning promise to scale the analysis of data to a degree that was not possible by human analysts, combing through digital traces from social media, cell phone location data, or video footage from surveillance cameras to identify behavior patterns that people may not even realize they have or that they want to keep private. Data can further be aggregated into social credit systems designed to steer the behavior of entire populations. Surveillance technology can easily make mistakes and be abused for suppressing specific populations, not only in authoritarian regimes. This raises many ethical questions: To what degree is it ethical to contribute to weapons or surveillance systems? Are they inevitable? Could we build such systems responsibly, reducing their risks and unintended consequences?
Discrimination
While it was always possible to encode discriminatory rules in software code, intentional or not, and to underserve people from specific demographics by not recognizing or ignoring their requirements, concerns for algorithmic discrimination are rising with the increasing use of machine learning. As machine-learning algorithms learn decision rules from data, the model will learn also from bias in the data and reinforce that bias in decisions in the resulting system. For example, automated resume screening algorithms might learn from past discriminatory hiring practices and reject most female applicants. Machine learning can be presented as a neutral, objective tool for data-driven decision-making to replace biased humans, but it can just as easily reinforce or even amplify bias. So how proactive should responsible developers be in screening their system for bias?
Facets of Responsible ML Engineering
There is no agreed-upon definition of responsible or ethical ML engineering, and different organizations, researchers, and practitioners make different lists. For example, Microsoft lists its responsible AI principles as (1) fairness, (2) reliability and safety, (3) privacy and security, (4) inclusiveness, (5) transparency, and (6) accountability. Google lists its AI principles as (1) being socially beneficial, (2) avoiding unfair bias, (3) safety, (4) accountability, (5) privacy, (6) scientific excellence, and (7) responsible deployment. The European Union’s Ethics Guidelines for Trustworthy AI state ethical principles as (1) respect for human autonomy, (2) prevention of harm, (3) fairness, and (4) explicability, and it lists as key technical requirements (1) human agency and oversight, (2) technical robustness and safety, (3) privacy and data governance, (4) transparency, (5) diversity, non-discrimination, and fairness, (6) environmental and societal well-being, and (7) accountability. The Blueprint for AI Bill of Rights published by the US White House sets as principles (1) safe and effective systems, (2) algorithmic discrimination protections, (3) data privacy, (4) notice and explanation, and (5) human alternatives, consideration, and fallback. Overall, the nonprofit AlgorithmWatch cataloged 173 ethics guidelines at the time of this writing, summarizing that all of them include similar principles of transparency, equality/non-discrimination, accountability, and safety, while some additionally demand societal benefits and protecting human rights.
The remainder of the book will selectively cover responsible ML engineering topics. We will include two pieces of technical infrastructure that are essential technical building blocks for many responsible engineering activities and four areas of concern that crosscut the entire development lifecycle.
Additional technical infrastructure for responsible engineering:
-
Versioning, provenance, reproducibility: Being able to reproduce models and predictions, as well as track which specific model made a certain prediction and how that model was trained, can be essential for trusting and debugging a system and is an important building block in responsible engineering.
-
Interpretability and explainability: Considering to what degree developers and users can understand the internals of a model or derive explanations about the model or its prediction are important tools for responsible engineers when designing and auditing systems and when providing transparency to end users.
Covered areas of concern:
-
Fairness: Bias can easily sneak into machine-learned models used for making decisions. Responsible engineers must understand the possible harms of discrimination, the possible sources of biases, and the different notions of fairness. They must develop a plan to consider fairness throughout the entire development process, including both the model and system levels.
-
Safety: Even for systems that are unlikely to create lethal hazards, the uncertainty, feedback loops, and inscrutability introduced with machine-learning components often create safety risks. Responsible engineers must take safety seriously and must take steps throughout the entire life cycle, from requirements engineering and risk analysis to system design and quality assurance.
-
Security and privacy: Systems with machine-learning components can be attacked in multiple novel ways, and their heavy reliance on data raises many privacy concerns. Responsible engineers must evaluate their systems for possible security risks, deliberate about privacy, and take mitigating steps.
-
Transparency and accountability: For users to trust a software system with machine-learned models, they should be aware of the model, have some insights into how the model works, and be able to contest decisions. Responsible engineers should design mechanisms to hold people accountable for the system.
Regulation Is Coming
Ethical issues in software systems with machine-learning components have received extensive media and research attention in recent years, triggered by cases of discrimination and high-profile accidents. At the same time, technical capabilities are evolving quickly and may outpace regulation. There is an ongoing debate about the role of AI ethics and to what degree responsible practices should be encoded in laws and regulation. In this context, regulation refers to rules imposed by governments, whether directly through enacting laws or through empowering an agency to set rules; regulations are usually enforceable either by imposing penalties for violation or opening a path for legal action.
Regulation and Self-Regulation
For many years now, there have been calls for government regulation specifically targeted at the use of machine learning, with very little actual regulation emerging. Of course, existing non-ML-specific regulations still apply, such as anti-discrimination statutes, privacy rules, pre-market approval of medical devices, and safety standards for software in cars and planes. However, those often do not match the changed engineering practices when using machine learning, especially as some assumptions break with the lack of specifications and the increased importance of data.
There have been many working groups and whitepapers from various government bodies that discuss AI ethics, but little has resulted in concrete regulation so far. For example, in 2019, the president of the United States issued an executive order “Accelerating America’s Leadership in Artificial Intelligence,” which in tone suggested that innovation is more important than regulation. A subsequent 2020 White House white paper drafted guidance for future regulation for private sector AI, outlining many concerns, such as public trust in AI, public participation, risk management, and safety, but generally favored non-regulatory approaches. The aforementioned 2019 Ethics Guidelines for Trustworthy AI in Europe and the 2022 Blueprint for an AI Bill of Rights in the US outline principles and goals but are equally nonbinding, while actual regulation is debated.
At the time of finalizing this book in late 2023, the closest to actual serious regulation is the European Union’s Artificial Intelligence Act*.* The EU AI Act was first proposed by the European Commission in 2021 and was approved by the European Parliament in 2023, is expected to become law after more discussions and changes in 2024, and would come into effect about two years after that. The EU AI Act entirely outlaws some applications of machine learning considered to have unacceptable risks, such as social scoring, cognitive manipulation, and real-time biometric surveillance. In addition, it defines foundation models and machine-learning use in eight application areas, including education, hiring, and law enforcement, as high-risk. For those high-risk applications and models, the AI Act requires companies to register the system in a public database and imposes requirements for (ongoing) risk assessment, data governance, monitoring and incident reporting, documentation, transparency to users, human oversight, and assurances for robustness, security, and accuracy. For applications outside these high-risk domains, obligations are much lower and relate primarily to transparency. All other systems outside these domains are considered limited-risk or minimal-risk and have at most some transparency obligations to disclose the use of a model. The AI Act provides an overall framework, but the specific implementation in practice remains to be determined—for example, what specific practices are needed and what forms of evidence are needed to demonstrate compliance.
Another significant recent step that may lead to some regulation is the White House’s October 2023 Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. This executive order directs various agencies in the US to develop regulations or standards for various aspects of AI systems, including developing quality assurance standards and standards for marking AI-generated content. For very large models, it proposes reporting requirements where developers need to inform the government about the model and quality assurance steps taken. In addition, several agencies are instructed to develop guidelines for specific chemical, biological, radiological, nuclear, and cybersecurity risks. In general, the executive order is expansive and covers many ethics and responsible-engineering concerns. But rather than setting explicit enforceable rules, the executive order instructs other agencies to collect information, form committees, develop guidance, issue reports, or invest in research.
In the meantime, many big-tech companies have publicly adopted policies and guidelines around “AI ethics” or “responsible AI” on their websites, and some have established AI ethics councils, fund internal research groups on the topic, or support academic research initiatives. They argue that the industry can self-regulate, by identifying ethical and responsible practices and adopting them. Companies work with each other and with nonprofit and government organizations to develop guidelines and recommendations. Company representatives and many think pieces argue that companies have more expertise to do the right thing and are more agile than bureaucrats defining stifling and unrealistic rules. Companies often set ambitious goals and principles around AI ethics, develop training, and may adopt some practices as part of their processes.
In contrast to government regulation, there is no enforcement mechanism for self-regulation outside the organization. The organization can decide what ethics goals and principles to pursue and has discretion of how to implement them.
Ethics Bashing and Ethics Washing
While many developers will be truly interested in being more responsible in their development practices, the current discussions on ethics and safety in machine learning, especially when framed through self-regulation, have their critics.
Some perceive the public discussions of AI ethics, the setting of goals and declaring principles and self-enforced policies, and the funding of AI ethics research of big tech companies as ethics washing—an attempt to provide an acceptable facade to justify deregulation and self-regulation in the market. The argument of these critics is that companies instrumentalize the language of ethics, but eventually pay little attention to actually effective practices, especially when they do not align with business goals. They may point to long-term existential risks, such as a widely shared open letter calling for a six-month pause in the development of more powerful large language models in early 2023, while ignoring immediate real-world harms caused by existing systems. Such a self-regulation strategy might be a distractions or might primarily address symptoms rather than causes of problems. It has little teeth for enforcing actual change. Journalists and researchers have written many articles about how companies are trying to take over the narrative on AI ethics to avoid regulation.
Some companies actually push for some regulation, but here critics are concerned about regulatory capture, the idea that companies might shape regulation such that it aligns with the company’s practices but at the same time raises the cost of business for all (by requiring costly compliance to regulation) and thus inhibiting competition from small and new organizations. In addition, some organizations seem to use public statements about AI ethics and safety as a mechanisms to advertise their own products as so powerful that we should we worried whether they are too powerful (“criti-hype”).
At the same time, in what is termed ethics bashing, some critics can go as far as dismissing the entire ethics discussion, because they see it only as a marketing tool or, worse, as a way to cover up unethical behavior. These critics consider ethics as an intellectual “ivory tower” activity with little practical contributions to real system building. Hence, some may dismiss ethical discussions entirely.
It is important to maintain a realistic view of ethical and responsible engineering practices. There are deep and challenging questions, such as what notion of fairness should be considered for any given system or who should be held accountable for harm done by a system. There are lots of ways in which developers can significantly reduce the risk from systems by following responsible engineering practices, such as hazard analysis to identify system risks, threat modeling for security analysis, providing explanations to audit models, and requiring human supervision. Even if not perfect, these can make significant contributions to improve safety, security, and fairness and to give humans more agency and dignity.
Do Not Wait for Regulation
It is widely expected that there will be more regulation around AI ethics and responsible engineering in the future. The US has a tendency to adopt regulation after particularly bad events, whereas Europe tends to be more proactive with the AI Act. We may see more targeted regulation for specific areas such as autonomous vehicles, biomedical research, or government-sector systems. Some regulatory bodies may clarify how they intend to enforce existing regulation—for example, in April 2021, the US’s Federal Trade Commission publicly posted that they interpret the Section 5 of the FTC Act enacted in 1914, which prohibits unfair and deceptive practices, to prohibit the sale or use of racially biased algorithms as well. In addition, industry groups might develop their own standards and, over time, not using them may be considered negligence.
However, we argue that responsible engineers should not wait for regulation but get informed about possible problems and responsible engineering practices to avoid or mitigate such problems before they lead to harm, regulation or not.
Summary
Software with and without machine learning can potentially cause significant harm when deployed as part of a system. Machine learning has the potential to amplify many concerns, including safety, manipulation, polarization, job loss, weapons, and discrimination. With a few lines of code, developers can have outsized power to affect individuals and societies—and they may not even realize it. While current regulation is sparse and software engineers have traditionally been successful in mostly avoiding liability for their code, there are plenty of reasons to strive to behave ethically and to develop software responsibly. Ethical AI and what exactly responsible development entails are broadly discussed and often includes concerns about fairness, safety, security, and transparency, which we will explore in the following chapters.
Further Readings
-
A good introduction to AI ethics and various concerns for a nontechnical audience: 🗎 Donovan, Joan, Robyn Caplan, Jeanna Matthews, and Lauren Hanson. “Algorithmic Accountability: A primer.” Technical Report (2018).
-
An overview of eighty-four AI ethics guidelines, identifying common principles and goals, and AlgorithmWatch’s index of 173 guidelines: 🗎 Jobin, Anna, Marcello Ienca, and Effy Vayena. “The Global Landscape of AI Ethics Guidelines.” Nature Machine Intelligence 1, no. 9 (2019): 389–399. 🔗 https://inventory.algorithmwatch.org/.
-
An overview of risks from large language models: 🗎 Weidinger, Laura, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John Mellor, Amelia Glaese et al. “Taxonomy of Risks Posed by Language Models.” In Proceedings of the Conference on Fairness, Accountability, and Transparency, pp. 214–229. 2022.
-
The ACM Code of Ethics and Professional Conduct and IEEE’s Code of Ethics for Software Engineers are broad guidelines for computer scientists and software engineers, and several professional organizations have proposed code of ethics for data scientists: 🔗 https://ethics.acm.org 🔗 https://www.computer.org/education/code-of-ethics 🔗 http://datascienceassn.org/code-of-conduct.html.
-
An in-depth discussion of critiques about ethics (ethics washing, ethics bashing) and the role that philosophy can play in AI ethics: 🗎 Bietti, Elettra. “From Ethics Washing to Ethics Bashing: A View on Tech Ethics from Within Moral Philosophy.” In Proceedings of the Conference on Fairness, Accountability, and Transparency, pp. 210–219. 2020.
-
Examples of papers and media articles critical of self-regulation on AI ethics: 🗎 Greene, Daniel, Anna Lauren Hoffmann, and Luke Stark. “Better, Nicer, Clearer, Fairer: A Critical Assessment of the Movement for Ethical Artificial Intelligence and Machine Learning.” In Proceedings of the Hawaii International Conference on System Sciences, 2019. 🗎 Metcalf, Jacob, and Emanuel Moss. “Owning Ethics: Corporate Logics, Silicon Valley, and the Institutionalization of Ethics.” Social Research: An International Quarterly 86, no. 2 (2019): 449–476. 📰 Ochigame, Rodrigo. “The Invention of 'Ethical AI': How Big Tech Manipulates Academia to Avoid Regulation.” The Intercept, 2019.
-
Examples of criticizing concerns about AI ethics as wishful worries or critihype: 📰 Vinsel, Lee. “You’re Doing It Wrong: Notes on Criticism and Technology Hype.” [blog post], 2021. 📰 Bender, Emily M. “On AI Doomerism.” Critical AI, 2023. 📰 Kapoor, Sayash and Arvind Narayanan. “A Misleading Open Letter about Sci-fi AI Dangers Ignores the Real Risks.” [blog post], 2023.
As all chapters, this text is released under Creative Commons BY-NC-ND 4.0 license. Last updated on 2024-06-10.